Although the commands below are replicated in the Cloudera Whirr install doc, I find it helpful to document my own experiences, as I usually encounter errors not mentioned in the documentation.
Whirr Configuration
linux-z6tw:~> whirr version
Apache Whirr 0.3.0-CDH3B4
linux-z6tw:~> cat hadoop.properties
whirr.service-name=hadoop
whirr.cluster-name=myhadoopcluster
whirr.instance-templates=1 jt+nn,1 dn+tt
whirr.provider=ec2
whirr.identity=0TM8DSRMM
whirr.credential=VhmAq9QzCxzKpxhQxBoA5jO
whirr.private-key-file=${sys:user.home}/.ssh/id_rsa
whirr.public-key-file=${sys:user.home}/.ssh/id_rsa.pub
whirr.hadoop-install-runurl=cloudera/cdh/install
whirr.hadoop-configure-runurl=cloudera/cdh/post-configure
Launching a Whirr Cluster
linux-z6tw:~> whirr launch-cluster --config hadoop.properties
Bootstrapping cluster
Configuring template
Starting 1 node(s) with roles [tt, dn]
Configuring template
Starting 1 node(s) with roles [jt, nn]
Nodes started: [[id=us-east-1/i-c4e942ab, providerId=i-c4e942ab, tag=myhadoopcluster, name=null, location=[id=us-east-1d, scope=ZONE, description=us-east-1d, parent=us-east-1], uri=null, imageId=us-east-1/ami-2a1fec43, os=[name=null, family=amzn-linux, version=2011.02.1, arch=paravirtual, is64Bit=false, description=amzn-ami-us-east-1/amzn-ami-2011.02.1.i386.manifest.xml], userMetadata={}, state=RUNNING, privateAddresses=[10.116.209.9], publicAddresses=[50.17.125.68], hardware=[id=m1.small, providerId=m1.small, name=m1.small, processors=[[cores=1.0, speed=1.0]], ram=1740, volumes=[[id=null, type=LOCAL, size=10.0, device=/dev/sda1, durable=false, isBootDevice=true], [id=null, type=LOCAL, size=150.0, device=/dev/sda2, durable=false, isBootDevice=false]], supportsImage=Not(is64Bit())]]]
Nodes started: [[id=us-east-1/i-c0e942af, providerId=i-c0e942af, tag=myhadoopcluster, name=null, location=[id=us-east-1d, scope=ZONE, description=us-east-1d, parent=us-east-1], uri=null, imageId=us-east-1/ami-2a1fec43, os=[name=null, family=amzn-linux, version=2011.02.1, arch=paravirtual, is64Bit=false, description=amzn-ami-us-east-1/amzn-ami-2011.02.1.i386.manifest.xml], userMetadata={}, state=RUNNING, privateAddresses=[10.101.11.193], publicAddresses=[184.72.91.22], hardware=[id=m1.small, providerId=m1.small, name=m1.small, processors=[[cores=1.0, speed=1.0]], ram=1740, volumes=[[id=null, type=LOCAL, size=10.0, device=/dev/sda1, durable=false, isBootDevice=true], [id=null, type=LOCAL, size=150.0, device=/dev/sda2, durable=false, isBootDevice=false]], supportsImage=Not(is64Bit())]]]
Authorizing firewall
Running configuration script
Configuration script run completed
Running configuration script
Configuration script run completed
Completed configuration of myhadoopcluster
Web UI available at http://ec2-184-72-91-22.compute-1.amazonaws.com
Wrote Hadoop site file /home/sodo/.whirr/myhadoopcluster/hadoop-site.xml
Wrote Hadoop proxy script /home/sodo/.whirr/myhadoopcluster/hadoop-proxy.sh
Wrote instances file /home/sodo/.whirr/myhadoopcluster/instances
Started cluster of 2 instances
Cluster{instances=[Instance{roles=[jt, nn], publicAddress=/184.72.91.22, privateAddress=/10.101.11.193, id=us-east-1/i-c0e942af}, Instance{roles=[tt, dn], publicAddress=/50.17.125.68, privateAddress=/10.116.209.9, id=us-east-1/i-c4e942ab}], configuration={hadoop.job.ugi=root,root, mapred.job.tracker=ec2-184-72-91-22.compute-1.amazonaws.com:8021, hadoop.socks.server=localhost:6666, fs.s3n.awsAccessKeyId=058DSRMMTF, fs.s3.awsSecretAccessKey=VhmOHmAq9QzCxzKpxhQxBoA5jOxZksq62jpO5mbD, fs.s3.awsAccessKeyId=058DSRMMTF, hadoop.rpc.socket.factory.class.default=org.apache.hadoop.net.SocksSocketFactory, fs.default.name=hdfs://ec2-184-72-91-22.compute-1.amazonaws.com:8020/, fs.s3n.awsSecretAccessKey=VhmAq9QzCxzKpxhQxBoA5jOxZks}}
Update the local Hadoop configuration to use hadoop-site.xml
linux-z6tw:~> ls .whirr/myhadoopcluster/
hadoop-proxy.sh hadoop-site.xml instances
linux-z6tw:~> sudo cp -r /etc/hadoop-0.20/conf.empty /etc/hadoop-0.20/conf.whirr
root's password:
linux-z6tw:~> sudo rm -f /etc/hadoop-0.20/conf.whirr/*-site.xml
sudo rm -f /etc/hadoop-0.20/conf.whirr/*-site.xml
linux-z6tw:~> sudo cp ~/.whirr/myhadoopcluster/hadoop-site.xml /etc/hadoop-0.20/conf.whirr
linux-z6tw:/> sudo /usr/sbin/update-alternatives --install /etc/hadoop-0.20/conf hadoop-0.20-conf /etc/hadoop-0.20/conf.whirr 50
linux-z6tw:/> /usr/sbin/update-alternatives --display hadoop-0.20-conf
hadoop-0.20-conf - status is auto.
link currently points to /etc/hadoop-0.20/conf.whirr
/etc/hadoop-0.20/conf.empty - priority 10
/etc/hadoop-0.20/conf.pseudo - priority 30
/etc/hadoop-0.20/conf.whirr - priority 50
Current `best' version is /etc/hadoop-0.20/conf.whirr.
Running a Whirr Proxy
linux-z6tw:/> . ~/.whirr/myhadoopcluster/hadoop-proxy.sh
Running proxy to Hadoop cluster at ec2-50-17-36-127.compute-1.amazonaws.com. Use Ctrl-c to quit.
Warning: Permanently added 'ec2-50-17-36-127.compute-1.amazonaws.com,10.194.74.132' (RSA) to the list of known hosts.
Hadoop Commands
Error: You get this error if you don't have the proxy running:
linux-z6tw:/> hadoop fs -ls /
11/03/31 01:53:08 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively
11/03/31 01:53:10 INFO ipc.Client: Retrying connect to server: ec2-184-72-91-22.compute-1.amazonaws.com/184.72.91.22:8020. Already tried 0 time(s).
11/03/31 01:53:11 INFO ipc.Client: Retrying connect to server: ec2-184-72-91-22.compute-1.amazonaws.com/184.72.91.22:8020. Already tried 1 time(s).
11/03/31 01:53:12 INFO ipc.Client: Retrying connect to server: ec2-184-72-91-22.compute-1.amazonaws.com/184.72.91.22:8020. Already tried 2 time(s).
11/03/31 01:53:13 INFO ipc.Client: Retrying connect to server: ec2-184-72-91-22.compute-1.amazonaws.com/184.72.91.22:8020. Already tried 3 time(s).
11/03/31 01:53:14 INFO ipc.Client: Retrying connect to server: ec2-184-72-91-22.compute-1.amazonaws.com/184.72.91.22:8020. Already tried 4 time(s).
^Csodo@linux-z6tw:/>
linux-z6tw:~/.whirr/myhadoopcluster> hadoop fs -ls /
Found 4 items
drwxrwxrwx - hdfs supergroup 0 2011-03-31 01:43 /hadoop
drwxrwxrwx - hdfs supergroup 0 2011-03-31 01:43 /mnt
drwxrwxrwx - hdfs supergroup 0 2011-03-31 01:43 /tmp
drwxrwxrwx - hdfs supergroup 0 2011-03-31 01:43 /user
linux-z6tw:~> hadoop fs -mkdir input
linux-z6tw:~> hadoop fs -put /usr/lib/hadoop-0.20/LICENSE.txt input
linux-z6tw:~> hadoop fs -ls /user/sodo/input
Found 1 items
-rw-r--r-- 3 sodo supergroup 13366 2011-03-31 02:02 /user/sodo/input/LICENSE.txt
MapReduce Test
linux-z6tw:~> hadoop jar /usr/lib/hadoop-0.20/hadoop-examples-*.jar wordcount input output
11/03/31 02:07:53 INFO input.FileInputFormat: Total input paths to process : 1
11/03/31 02:07:54 INFO mapred.JobClient: Running job: job_201103310543_0001
11/03/31 02:07:55 INFO mapred.JobClient: map 0% reduce 0%
11/03/31 02:08:07 INFO mapred.JobClient: map 100% reduce 0%
11/03/31 02:08:23 INFO mapred.JobClient: map 100% reduce 100%
11/03/31 02:08:27 INFO mapred.JobClient: Job complete: job_201103310543_0001
11/03/31 02:08:27 INFO mapred.JobClient: Counters: 22
11/03/31 02:08:27 INFO mapred.JobClient: Job Counters
11/03/31 02:08:27 INFO mapred.JobClient: Launched reduce tasks=1
11/03/31 02:08:27 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=12167
11/03/31 02:08:27 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
11/03/31 02:08:27 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
11/03/31 02:08:27 INFO mapred.JobClient: Launched map tasks=1
11/03/31 02:08:27 INFO mapred.JobClient: Data-local map tasks=1
11/03/31 02:08:27 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=15843
11/03/31 02:08:27 INFO mapred.JobClient: FileSystemCounters
11/03/31 02:08:27 INFO mapred.JobClient: FILE_BYTES_READ=10206
11/03/31 02:08:27 INFO mapred.JobClient: HDFS_BYTES_READ=13508
11/03/31 02:08:27 INFO mapred.JobClient: FILE_BYTES_WRITTEN=114918
11/03/31 02:08:27 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=7376
11/03/31 02:08:27 INFO mapred.JobClient: Map-Reduce Framework
11/03/31 02:08:27 INFO mapred.JobClient: Reduce input groups=714
11/03/31 02:08:27 INFO mapred.JobClient: Combine output records=714
11/03/31 02:08:27 INFO mapred.JobClient: Map input records=244
11/03/31 02:08:27 INFO mapred.JobClient: Reduce shuffle bytes=10206
11/03/31 02:08:27 INFO mapred.JobClient: Reduce output records=714
11/03/31 02:08:27 INFO mapred.JobClient: Spilled Records=1428
11/03/31 02:08:27 INFO mapred.JobClient: Map output bytes=19699
11/03/31 02:08:27 INFO mapred.JobClient: Combine input records=1887
11/03/31 02:08:27 INFO mapred.JobClient: Map output records=1887
11/03/31 02:08:27 INFO mapred.JobClient: SPLIT_RAW_BYTES=142
11/03/31 02:08:27 INFO mapred.JobClient: Reduce input records=714
More Hadoop Commands
linux-z6tw:~> hadoop fs -ls /user/sodo
Found 3 items
drwx------ - sodo supergroup 0 2011-03-31 02:04 /user/sodo/.staging
drwxr-xr-x - sodo supergroup 0 2011-03-31 02:02 /user/sodo/input
drwxrwxrwx - sodo supergroup 0 2011-03-31 02:04 /user/sodo/output
linux-z6tw:~> hadoop fs -ls /user/sodo/output
Found 3 items
-rw-r--r-- 3 sodo supergroup 0 2011-03-31 02:04 /user/sodo/output/_SUCCESS
drwxrwxrwx - sodo supergroup 0 2011-03-31 02:03 /user/sodo/output/_logs
-rw-r--r-- 3 sodo supergroup 7376 2011-03-31 02:04 /user/sodo/output/part-r-00000
linux-z6tw:~> hadoop fs -cat /user/sodo/output/part-* | head
"AS 3
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE" 1
"Not 1
cat: Unable to write to output stream.
Verify SSH connectivity
sodo@linux-z6tw:~/trendingtopics> ssh ec2-user@ec2-204-236-240-136.compute-1.amazonaws.com
Last login: Sun Apr 3 15:35:18 2011 from c-69-248-248-90.hsd1.nj.comcast.net
__| __|_ ) Amazon Linux AMI
_| ( / Beta
___|\___|___|
See /usr/share/doc/system-release-2011.02 for latest release notes. :-)
[ec2-user@ip-10-114-102-177 ~]$ exit
logout
Connection to ec2-204-236-240-136.compute-1.amazonaws.com closed
Hadoop Update script
sodo@linux-z6tw:~/trendingtopics> cat ~/updateHadoopConfig.sh
#!/bin/bash -v
whirr version
cat hadoop.properties
echo "Launch the cluster..hit ENTER"
read ANSWER
whirr launch-cluster --config hadoop.properties
ls .whirr/myhadoopcluster/
echo "Update the local Hadoop configuration to use hadoop-site.xml..hit ENTER"
read ANSWER
sudo cp -r /etc/hadoop-0.20/conf.empty /etc/hadoop-0.20/conf.whirr
sudo rm -f /etc/hadoop-0.20/conf.whirr/*-site.xml
sudo cp ~/.whirr/myhadoopcluster/hadoop-site.xml /etc/hadoop-0.20/conf.whirr
sudo /usr/sbin/update-alternatives --install /etc/hadoop-0.20/conf hadoop-0.20-conf /etc/hadoop-0.20/conf.whirr 50
sudo /usr/sbin/update-alternatives --display hadoop-0.20-conf
echo "Now, run the proxy..hit ENTER"
read ANSWER
. ~/.whirr/myhadoopcluster/hadoop-proxy.sh
MapReduce Test Script
sfrase@linux-z6tw:~> cat mapReduceTestJob.sh
#!/bin/bash -v
hadoop fs -mkdir input
hadoop fs -put $HADOOP_HOME/LICENSE.txt input
hadoop jar $HADOOP_HOME/hadoop-examples-*.jar wordcount input output
hadoop fs -cat output/part-* | head
Reference
Hadoop Command Reference
Hadoop Streaming
How MapReduce Works
Wednesday, March 30, 2011
Saturday, March 26, 2011
Cloudera for Hadoop, Beta 3 install and Whirr
I needed a test bed, so I fired up a micro OpenSuSE 11.4 instance on EC2 as it is relatively cheap (0.02 per Micro Instance, at the time of this writing). I'll build a VM for this purpose later, but it is late in the evening and I just want to get something working.
Once I had a vm running, I then went through the install docs and got both Cloudera for Hadoop Beta 3 and Whirr installed. Finally, I was able to fire up a cluster using Whirr. I describe Whirr configuration, Hadoop commands and perform a quick MapReduce test in a follow-up post.
Cloudera for Hadoop Beta 3
Following https://docs.cloudera.com/display/DOC/CDH3+Quick+Start+Guide
Following instructions here..
https://wiki.cloudera.com/display/DOC/Whirr+Installation
Whirr Notes
ip-10-212-121-180:~ # cat .bashrc
alias whirr='java -jar /usr/lib/whirr/whirr-cli-0.3.0-CDH3B4.jar'
alias whirr-ec2='whirr --identity=058DSRMMTFQMQRER2 --credential=VHmAq9QzCxzKpxhQxBoA5jOxZksq62jpO5mbD'
ip-10-212-121-180:~ # cat .bash_profile
export WHIRR_HOME=/usr/lib/whirr
export AWS_ACCESS_KEY_ID="058DSRMMT"
export AWS_SECRET_ACCESS_KEY="VHmAq9QzCxzKpxhQxBoA5jOxZks"
Hadoop Properties
ip-10-212-121-180:~ # cat hadoop.properties
whirr.cluster-name=myhadoopcluster
whirr.instance-templates=1 jt+nn,1 dn+tt
whirr.provider=ec2
whirr.identity=${env:AWS_ACCESS_KEY_ID}
whirr.credential=${env:AWS_SECRET_ACCESS_KEY}
whirr.private-key-file=${sys:user.home}/.ssh/id_rsa
whirr.public-key-file=${sys:user.home}/.ssh/id_rsa.pub
Passphraseless SSH for Localhost
ip-10-212-121-180:~ # ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
*make sure you ssh login as ec2-user to any hadoop cluster members
Launching a Hadoop cluster with Whirr
ip-10-212-121-180:~ # whirr launch-cluster --config hadoop.properties ip-10-212-121-180:~
#
Bootstrapping cluster
Configuring template
Starting 1 node(s) with roles [tt, dn]
Configuring template
Starting 1 node(s) with roles [jt, nn]
Nodes started: [[id=us-east-1/i-2a55fb45, providerId=i-2a55fb45, tag=myhadoopcluster, name=null, location=[id=us-east-1d, scop
e=ZONE, description=us-east-1d, parent=us-east-1], uri=null, imageId=us-east-1/ami-2a1fec43, os=[name=null, family=amzn-linux,
version=2011.02.1, arch=paravirtual, is64Bit=false, description=amzn-ami-us-east-1/amzn-ami-2011.02.1.i386.manifest.xml], use
rMetadata={}, state=RUNNING, privateAddresses=[10.98.103.208], publicAddresses=[184.72.64.110], hardware=[id=m1.small, provide
rId=m1.small, name=m1.small, processors=[[cores=1.0, speed=1.0]], ram=1740, volumes=[[id=null, type=LOCAL, size=10.0, device=/
dev/sda1, durable=false, isBootDevice=true], [id=null, type=LOCAL, size=150.0, device=/dev/sda2, durable=false, isBootDevice=f
alse]], supportsImage=Not(is64Bit())]]]
Nodes started: [[id=us-east-1/i-c455fbab, providerId=i-c455fbab, tag=myhadoopcluster, name=null, location=[id=us-east-1d, scop
e=ZONE, description=us-east-1d, parent=us-east-1], uri=null, imageId=us-east-1/ami-2a1fec43, os=[name=null, family=amzn-linux,
version=2011.02.1, arch=paravirtual, is64Bit=false, description=amzn-ami-us-east-1/amzn-ami-2011.02.1.i386.manifest.xml], use
rMetadata={}, state=RUNNING, privateAddresses=[10.112.27.95], publicAddresses=[67.202.27.150], hardware=[id=m1.small, provider
Id=m1.small, name=m1.small, processors=[[cores=1.0, speed=1.0]], ram=1740, volumes=[[id=null, type=LOCAL, size=10.0, device=/d
ev/sda1, durable=false, isBootDevice=true], [id=null, type=LOCAL, size=150.0, device=/dev/sda2, durable=false, isBootDevice=fa
lse]], supportsImage=Not(is64Bit())]]]
Authorizing firewall
Running configuration script
Configuration script run completed
Running configuration script
Configuration script run completed
Completed configuration of myhadoopcluster
Web UI available at http://ec2-67-202-27-150.compute-1.amazonaws.com
Wrote Hadoop site file /root/.whirr/myhadoopcluster/hadoop-site.xml
Wrote Hadoop proxy script /root/.whirr/myhadoopcluster/hadoop-proxy.sh
Wrote instances file /root/.whirr/myhadoopcluster/instances
Started cluster of 2 instances
Cluster{instances=[Instance{roles=[tt, dn], publicAddress=/184.72.64.110, privateAddress=/10.98.103.208, id=us-east-1/i-2a55fb
45}, Instance{roles=[jt, nn], publicAddress=/67.202.27.150, privateAddress=/10.112.27.95, id=us-east-1/i-c455fbab}], configura
tion={hadoop.job.ugi=root,root, mapred.job.tracker=ec2-67-202-27-150.compute-1.amazonaws.com:8021, hadoop.socks.server=localho
st:6666, fs.s3n.awsAccessKeyId=05TNM8DSRMM, fs.s3.awsSecretAccessKey=VhmAq9QzCxzKpxhQxBoA5jOxZksq62jpO5mbD, fs.s3.
awsAccessKeyId=058DSRM, hadoop.rpc.socket.factory.class.default=org.apache.hadoop.net.SocksSocketFactory, fs.defa
ult.name=hdfs://ec2-67-202-27-150.compute-1.amazonaws.com:8020/, fs.s3n.awsSecretAccessKey=VhmAq9QzCxzKpxhQxBoA5j
O5mbD}}
Destroying a Cluster
ip-10-212-121-180:~ # whirr destroy-cluster --config hadoop.properties
Destroying myhadoopcluster cluster
Cluster myhadoopcluster destroyed
More Whirr, Hadoop and MapReduce testing here
References
CDH3 Beta install and test cases
https://docs.cloudera.com/display/DOC/CDH3+Quick+Start+Guide
Pseudo-distributed mode and passphraseless SSH
http://archive.cloudera.com/cdh/3/hadoop-0.20.2-CDH3B4/single_node_setup.html
https://cwiki.apache.org/confluence/display/WHIRR/Quick+Start+Guide
http://incubator.apache.org/whirr/quick-start-guide.html (for MapReduce jobs sample)
Hadoop Shell Commands
Once I had a vm running, I then went through the install docs and got both Cloudera for Hadoop Beta 3 and Whirr installed. Finally, I was able to fire up a cluster using Whirr. I describe Whirr configuration, Hadoop commands and perform a quick MapReduce test in a follow-up post.
Cloudera for Hadoop Beta 3
Following https://docs.cloudera.com/display/DOC/CDH3+Quick+Start+Guide
- installed JDK (http://www.oracle.com/technetwork/java/javase/downloads/index.html)
- added Cloudera repo (zypper addrepo -f http://archive.cloudera.com/sles/11/x86_64/cdh/cloudera-cdh3.repo)
- zypper install hadoop-0.20-conf-pseudo
- testing
Following instructions here..
https://wiki.cloudera.com/display/DOC/Whirr+Installation
Whirr Notes
ip-10-212-121-180:~ # cat .bashrc
alias whirr='java -jar /usr/lib/whirr/whirr-cli-0.3.0-CDH3B4.jar'
alias whirr-ec2='whirr --identity=058DSRMMTFQMQRER2 --credential=VHmAq9QzCxzKpxhQxBoA5jOxZksq62jpO5mbD'
ip-10-212-121-180:~ # cat .bash_profile
export WHIRR_HOME=/usr/lib/whirr
export AWS_ACCESS_KEY_ID="058DSRMMT"
export AWS_SECRET_ACCESS_KEY="VHmAq9QzCxzKpxhQxBoA5jOxZks"
Hadoop Properties
ip-10-212-121-180:~ # cat hadoop.properties
whirr.cluster-name=myhadoopcluster
whirr.instance-templates=1 jt+nn,1 dn+tt
whirr.provider=ec2
whirr.identity=${env:AWS_ACCESS_KEY_ID}
whirr.credential=${env:AWS_SECRET_ACCESS_KEY}
whirr.private-key-file=${sys:user.home}/.ssh/id_rsa
whirr.public-key-file=${sys:user.home}/.ssh/id_rsa.pub
Passphraseless SSH for Localhost
ip-10-212-121-180:~ # ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
*make sure you ssh login as ec2-user to any hadoop cluster members
Launching a Hadoop cluster with Whirr
ip-10-212-121-180:~ # whirr launch-cluster --config hadoop.properties ip-10-212-121-180:~
#
Bootstrapping cluster
Configuring template
Starting 1 node(s) with roles [tt, dn]
Configuring template
Starting 1 node(s) with roles [jt, nn]
Nodes started: [[id=us-east-1/i-2a55fb45, providerId=i-2a55fb45, tag=myhadoopcluster, name=null, location=[id=us-east-1d, scop
e=ZONE, description=us-east-1d, parent=us-east-1], uri=null, imageId=us-east-1/ami-2a1fec43, os=[name=null, family=amzn-linux,
version=2011.02.1, arch=paravirtual, is64Bit=false, description=amzn-ami-us-east-1/amzn-ami-2011.02.1.i386.manifest.xml], use
rMetadata={}, state=RUNNING, privateAddresses=[10.98.103.208], publicAddresses=[184.72.64.110], hardware=[id=m1.small, provide
rId=m1.small, name=m1.small, processors=[[cores=1.0, speed=1.0]], ram=1740, volumes=[[id=null, type=LOCAL, size=10.0, device=/
dev/sda1, durable=false, isBootDevice=true], [id=null, type=LOCAL, size=150.0, device=/dev/sda2, durable=false, isBootDevice=f
alse]], supportsImage=Not(is64Bit())]]]
Nodes started: [[id=us-east-1/i-c455fbab, providerId=i-c455fbab, tag=myhadoopcluster, name=null, location=[id=us-east-1d, scop
e=ZONE, description=us-east-1d, parent=us-east-1], uri=null, imageId=us-east-1/ami-2a1fec43, os=[name=null, family=amzn-linux,
version=2011.02.1, arch=paravirtual, is64Bit=false, description=amzn-ami-us-east-1/amzn-ami-2011.02.1.i386.manifest.xml], use
rMetadata={}, state=RUNNING, privateAddresses=[10.112.27.95], publicAddresses=[67.202.27.150], hardware=[id=m1.small, provider
Id=m1.small, name=m1.small, processors=[[cores=1.0, speed=1.0]], ram=1740, volumes=[[id=null, type=LOCAL, size=10.0, device=/d
ev/sda1, durable=false, isBootDevice=true], [id=null, type=LOCAL, size=150.0, device=/dev/sda2, durable=false, isBootDevice=fa
lse]], supportsImage=Not(is64Bit())]]]
Authorizing firewall
Running configuration script
Configuration script run completed
Running configuration script
Configuration script run completed
Completed configuration of myhadoopcluster
Web UI available at http://ec2-67-202-27-150.compute-1.amazonaws.com
Wrote Hadoop site file /root/.whirr/myhadoopcluster/hadoop-site.xml
Wrote Hadoop proxy script /root/.whirr/myhadoopcluster/hadoop-proxy.sh
Wrote instances file /root/.whirr/myhadoopcluster/instances
Started cluster of 2 instances
Cluster{instances=[Instance{roles=[tt, dn], publicAddress=/184.72.64.110, privateAddress=/10.98.103.208, id=us-east-1/i-2a55fb
45}, Instance{roles=[jt, nn], publicAddress=/67.202.27.150, privateAddress=/10.112.27.95, id=us-east-1/i-c455fbab}], configura
tion={hadoop.job.ugi=root,root, mapred.job.tracker=ec2-67-202-27-150.compute-1.amazonaws.com:8021, hadoop.socks.server=localho
st:6666, fs.s3n.awsAccessKeyId=05TNM8DSRMM, fs.s3.awsSecretAccessKey=VhmAq9QzCxzKpxhQxBoA5jOxZksq62jpO5mbD, fs.s3.
awsAccessKeyId=058DSRM, hadoop.rpc.socket.factory.class.default=org.apache.hadoop.net.SocksSocketFactory, fs.defa
ult.name=hdfs://ec2-67-202-27-150.compute-1.amazonaws.com:8020/, fs.s3n.awsSecretAccessKey=VhmAq9QzCxzKpxhQxBoA5j
O5mbD}}
Destroying a Cluster
ip-10-212-121-180:~ # whirr destroy-cluster --config hadoop.properties
Destroying myhadoopcluster cluster
Cluster myhadoopcluster destroyed
More Whirr, Hadoop and MapReduce testing here
References
CDH3 Beta install and test cases
https://docs.cloudera.com/display/DOC/CDH3+Quick+Start+Guide
Pseudo-distributed mode and passphraseless SSH
http://archive.cloudera.com/cdh/3/hadoop-0.20.2-CDH3B4/single_node_setup.html
https://cwiki.apache.org/confluence/display/WHIRR/Quick+Start+Guide
http://incubator.apache.org/whirr/quick-start-guide.html (for MapReduce jobs sample)
Hadoop Shell Commands
Friday, March 25, 2011
ec2 ami, ebs and s3 storage
Following up on my previous post, I am trying to replicate DataWrangling's excellent TrendingTopics website using Amazon's EC2 cloud and Hadoop. The first part of DW's instructions was to get Cloudera's Hadoop installed and successfully tested. So far, so good as my previous post showed.
Today's Goal
Next, DataWrangling was to have me fire up a virtual machine in the EC2 cloud, create a chunk of storage and copy over some files to later munge through with Hadoop. I thought this would have been easy, but Amazon's litany of access, secret keys and gpg keypairs proved to be roadblocks. Until I read the appropriate section in the manual that told me what each one did:
A few years back I had played around with EC2, but my memory has grown foggy since then. It was time to bite the bullet and figure out this latest installment of Amazon Web Services.
AWS Management
The main thing to learn about Amazon Web Services is that you can manage the various services like EC2 and S3 in two ways:
1) via the AWS Management Console
2) via Amazon EC2 command line tools download from here
I started off using the management console to fire up a virtual machine or what Amazon calls an Amazon Machine Image (ami). Doing this via the console was easy enough. I simply logged and started configuring an ami. However, I noticed that most of DataWrangling's instructions used the command line tools. So I decided to tackle the AWS Toolkit install.
Again, the download for the command line tools is here. The tools are java based, so they run on any platform. Prereqs are a java jre along with a couple of environment variables, like so:
export EC2_HOME=/usr/bin/ec2-api-tools-1.4.1.2
export JAVA_HOME=/usr
Once the toolkit was installed and the tools accessible via the path, the tools rely on another two environment variables for access to the AWS environment:
export EC2_PRIVATE_KEY=/mnt/doc/software/amazon/certs/pk-QRHO7BYVS7ZI3ACWFSEZOB.pem
export EC2_CERT=/mnt/doc/software/amazon/certs/cert-BYVS7ZI3C2CWFSEBC7ZOB.pem
The X509 certs and private key above are found under Account -> Security credentials. Once the 509 certificates are created, the AWS tools come to life! If you don't have the proper certs, you'll see error messages like this:
[sodo@ogre ~]$ ec2-describe-instances
Client.MalformedSOAPSignature: Invalid SOAP Signature. Failed to check signature with X.509 cert
Here's a very nice explanation of the purpose and use of the different AWS certs and keys needed. Look for Mitch's response @ Oct 30, 2009 5:03 PM.
"Keep the x509 private key safe, because there is NO WAY to redownload it if you've lost it" http://www.amazon.com/gp/help/customer/display.html?ie=UTF8&nodeId=200123040
A handy test to validate the public and private key match is to compare the modulus output of the commands:
[sodo@ogre 509cert]$ openssl x509 -in cert-BYVS7ZI3C2CWFSEBC7ZOB.pem -text
[sodo@ogre 509cert]$ openssl rsa -in pk-QRHO7BYVS7ZI3ACWFSEZOB.pem -text
As long as they match, you're good to go!
Some EC2 commands
[sodo@ogre ~]$ ec2-describe-regions
REGION eu-west-1 ec2.eu-west-1.amazonaws.com
REGION us-east-1 ec2.us-east-1.amazonaws.com
REGION ap-northeast-1 ec2.ap-northeast-1.amazonaws.com
REGION us-west-1 ec2.us-west-1.amazonaws.com
REGION ap-southeast-1 ec2.ap-southeast-1.amazonaws.com
[sodo@ogre ~]$ ec2-describe-instances
RESERVATION r-e6cb234b 73784173 default
INSTANCE i-2134419 ami-5394733a ec2-XX-XX-XX-XX.compute-1.amazonaws.com running rook 0 m1.small us-east-1d
BLOCKDEVICE /dev/sdf vol-3e3c05 2011-03-26T03:53:39.000Z
Elastic Block Storage hosting the Wikipedia data
Once I had the base ami running, I added an Elastic Block Storage (EBS) volume that included a publically available snapshot of the Wikipedia logfile dataset..all 300GB of it! Neato.
[sodo@ogre ~]$ ec2-create-volume --snapshot snap-753dfc1c -z us-east-1d
VOLUME vol-6d3e0c05 320 snap-753dfc1c us-east-1d creating 2011-03-26T03:51:28+0000
[sodo@ogre ~]$ ec2-attach-volume vol-6d3e0c05 -i i-73e19 -d /dev/sdf
ATTACHMENT vol-6d3e0c05 i-73e19 /dev/sdf attaching 2011-03-26T03:53:31+0000
Writing to S3 Storage
I used the AWS Management tool to provision a storage bucket for myself. Here are a few S3 commands I learned along the way:
root@ec2-67-202-43-31:~# s3cmd ib s3://$MYBUCKET
Bucket 'sodotrendingtopics':
Location: any
root@ec2-67-202-43-31:~# s3cmd ls s3://$MYBUCKET
Bucket 'sodotrendingtopics':
2011-03-26 04:48 39158 s3://sodotrendingtopics/wikistats
I had access to the public dataset via the EBS, but the idea is that you connect to EBS and then copy off the data to an S3 storage bucket. At that point, you can then munge through the data with Hadoop, R or any other statistical tools you have. It was at the data copying stage where I hit a couple of snags:
1) I received a socket error trying to write files to my S3 storage:
root@ec2-production:/mnt/wikidata# time s3cmd put --force /mnt/wikidata/wikistats/pagecounts/pagecounts-20090401* s3://$MYBUCKET/wikistats/
Traceback (most recent call last):
File "/usr/bin/s3cmd", line 740, in
cmd_func(args)
..
File "", line 1, in sendall
socket.error: (32, 'Broken pipe')
This was because I had a capital letter in my S3 storage bucket name! ARGH! Luckily, someone had already encountered the problem. So I simply deleted my empty bucket and created a new one with an all lowercase name. Silly. By the way, another environment variable $MYBUCKET can be used if you don't feel like typing the name of your storage bucket all the time.
2) The DataWrangling command to copy over the Wikipedia log dataset did not work as expected. This command:
/mnt# time s3cmd put --force wikidata/wikistats/pagecounts/pagecounts-200904* s3://$MYBUCKET/wikistats/
Just kept on overwriting the wikistats directory and did not plop any files into the bucket. I changed the command to this:
for FILE in $(ls -1 pagecounts-200904*); do ls $FILE;time s3cmd put --force $FILE s3://sodotrendingtopics/wikistats/$FILE;echo;done
This way, the pagecounts files will get plopped into the s3 storage bucket directory properly. I decided to only copy over one month of data. This was about 40GB of data and took almost two hours to copy from EBS to my S3 bucket.
Long Day, but Success
In any case, that's been today's progress. Slow but sure. Next up:
Customizing the Cloudera Hadoop Ubuntu launch scripts
References
Amazon Web Services
Amazon S3 Beginner's Guide
DataWrangling's instructions
Amazon S3 FAQ (including charge calculator)
Understanding AWS Access Credentials
Download S3cmd
Today's Goal
Next, DataWrangling was to have me fire up a virtual machine in the EC2 cloud, create a chunk of storage and copy over some files to later munge through with Hadoop. I thought this would have been easy, but Amazon's litany of access, secret keys and gpg keypairs proved to be roadblocks. Until I read the appropriate section in the manual that told me what each one did:
- Amazon login and password to launch and administer Amazon EC2 instances through the AWS Management Console
- Access Key ID and Secret Access Key to launch and administer Amazon EC2 instances through the Query API and many UI-based tools (e.g., ElasticFox)
- X.509 certificate and private key to launch and administer Amazon EC2 instances through the SOAP API and command line interface
- Amazon EC2 Key Pair (SSH) enables you to connect to Linux/UNIX instances through SSH
- Tags key-value pair to simplify EC2 administration
A few years back I had played around with EC2, but my memory has grown foggy since then. It was time to bite the bullet and figure out this latest installment of Amazon Web Services.
AWS Management
The main thing to learn about Amazon Web Services is that you can manage the various services like EC2 and S3 in two ways:
1) via the AWS Management Console
2) via Amazon EC2 command line tools download from here
I started off using the management console to fire up a virtual machine or what Amazon calls an Amazon Machine Image (ami). Doing this via the console was easy enough. I simply logged and started configuring an ami. However, I noticed that most of DataWrangling's instructions used the command line tools. So I decided to tackle the AWS Toolkit install.
Again, the download for the command line tools is here. The tools are java based, so they run on any platform. Prereqs are a java jre along with a couple of environment variables, like so:
export EC2_HOME=/usr/bin/ec2-api-tools-1.4.1.2
export JAVA_HOME=/usr
Once the toolkit was installed and the tools accessible via the path, the tools rely on another two environment variables for access to the AWS environment:
export EC2_PRIVATE_KEY=/mnt/doc/software/amazon/certs/pk-QRHO7BYVS7ZI3ACWFSEZOB.pem
export EC2_CERT=/mnt/doc/software/amazon/certs/cert-BYVS7ZI3C2CWFSEBC7ZOB.pem
The X509 certs and private key above are found under Account -> Security credentials. Once the 509 certificates are created, the AWS tools come to life! If you don't have the proper certs, you'll see error messages like this:
[sodo@ogre ~]$ ec2-describe-instances
Client.MalformedSOAPSignature: Invalid SOAP Signature. Failed to check signature with X.509 cert
Here's a very nice explanation of the purpose and use of the different AWS certs and keys needed. Look for Mitch's response @ Oct 30, 2009 5:03 PM.
"Keep the x509 private key safe, because there is NO WAY to redownload it if you've lost it" http://www.amazon.com/gp/help/customer/display.html?ie=UTF8&nodeId=200123040
A handy test to validate the public and private key match is to compare the modulus output of the commands:
[sodo@ogre 509cert]$ openssl x509 -in cert-BYVS7ZI3C2CWFSEBC7ZOB.pem -text
[sodo@ogre 509cert]$ openssl rsa -in pk-QRHO7BYVS7ZI3ACWFSEZOB.pem -text
As long as they match, you're good to go!
Some EC2 commands
[sodo@ogre ~]$ ec2-describe-regions
REGION eu-west-1 ec2.eu-west-1.amazonaws.com
REGION us-east-1 ec2.us-east-1.amazonaws.com
REGION ap-northeast-1 ec2.ap-northeast-1.amazonaws.com
REGION us-west-1 ec2.us-west-1.amazonaws.com
REGION ap-southeast-1 ec2.ap-southeast-1.amazonaws.com
[sodo@ogre ~]$ ec2-describe-instances
RESERVATION r-e6cb234b 73784173 default
INSTANCE i-2134419 ami-5394733a ec2-XX-XX-XX-XX.compute-1.amazonaws.com running rook 0 m1.small us-east-1d
BLOCKDEVICE /dev/sdf vol-3e3c05 2011-03-26T03:53:39.000Z
Elastic Block Storage hosting the Wikipedia data
Once I had the base ami running, I added an Elastic Block Storage (EBS) volume that included a publically available snapshot of the Wikipedia logfile dataset..all 300GB of it! Neato.
[sodo@ogre ~]$ ec2-create-volume --snapshot snap-753dfc1c -z us-east-1d
VOLUME vol-6d3e0c05 320 snap-753dfc1c us-east-1d creating 2011-03-26T03:51:28+0000
[sodo@ogre ~]$ ec2-attach-volume vol-6d3e0c05 -i i-73e19 -d /dev/sdf
ATTACHMENT vol-6d3e0c05 i-73e19 /dev/sdf attaching 2011-03-26T03:53:31+0000
Writing to S3 Storage
I used the AWS Management tool to provision a storage bucket for myself. Here are a few S3 commands I learned along the way:
root@ec2-67-202-43-31:~# s3cmd ib s3://$MYBUCKET
Bucket 'sodotrendingtopics':
Location: any
root@ec2-67-202-43-31:~# s3cmd ls s3://$MYBUCKET
Bucket 'sodotrendingtopics':
2011-03-26 04:48 39158 s3://sodotrendingtopics/wikistats
I had access to the public dataset via the EBS, but the idea is that you connect to EBS and then copy off the data to an S3 storage bucket. At that point, you can then munge through the data with Hadoop, R or any other statistical tools you have. It was at the data copying stage where I hit a couple of snags:
1) I received a socket error trying to write files to my S3 storage:
root@ec2-production:/mnt/wikidata# time s3cmd put --force /mnt/wikidata/wikistats/pagecounts/pagecounts-20090401* s3://$MYBUCKET/wikistats/
Traceback (most recent call last):
File "/usr/bin/s3cmd", line 740, in
cmd_func(args)
..
File "", line 1, in sendall
socket.error: (32, 'Broken pipe')
This was because I had a capital letter in my S3 storage bucket name! ARGH! Luckily, someone had already encountered the problem. So I simply deleted my empty bucket and created a new one with an all lowercase name. Silly. By the way, another environment variable $MYBUCKET can be used if you don't feel like typing the name of your storage bucket all the time.
2) The DataWrangling command to copy over the Wikipedia log dataset did not work as expected. This command:
/mnt# time s3cmd put --force wikidata/wikistats/pagecounts/pagecounts-200904* s3://$MYBUCKET/wikistats/
Just kept on overwriting the wikistats directory and did not plop any files into the bucket. I changed the command to this:
for FILE in $(ls -1 pagecounts-200904*); do ls $FILE;time s3cmd put --force $FILE s3://sodotrendingtopics/wikistats/$FILE;echo;done
This way, the pagecounts files will get plopped into the s3 storage bucket directory properly. I decided to only copy over one month of data. This was about 40GB of data and took almost two hours to copy from EBS to my S3 bucket.
Long Day, but Success
In any case, that's been today's progress. Slow but sure. Next up:
Customizing the Cloudera Hadoop Ubuntu launch scripts
References
Amazon Web Services
Amazon S3 Beginner's Guide
DataWrangling's instructions
Amazon S3 FAQ (including charge calculator)
Understanding AWS Access Credentials
Download S3cmd
Thursday, March 24, 2011
Data driven website in the AWS cloud..oh boy!
After reading Semil Shah's excellent article on BigData, it started me thinking that there is a wellspring of data in my weblogs that I'm not taking advantage of. Peter Skomoroch got me psyched to try Hadoop and Cloudera with his Hadoop World talk on rapid prototyping of data intensive web apps. Pete posted a great guide on how to piece together the components for the site. I think it would be a great exercise to:
1) get a version of TrendingTopics.org site up and running.
2) apply that knowledge to big dataset management tasks back at work
Pete's guide is a fabulous open source resource. However, it has been two years since he wrote the application and a lot of the details about how each piece of software works have changed slightly or have been deprecated. (Funny how web technology techniques become obsoleted in two years!)
Rather than get into the nitty gritty details, I think it would be helpful to take a step back and visualize the architecture that I am trying to replicate as a whole. It is not inconsequential:
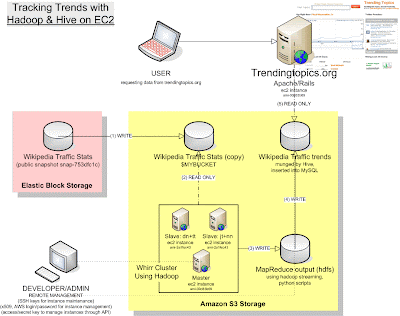
With that baseline set, I will delve into the more technical details of the project implementation in my upcoming posts.
next steps: getting a Cloudera-Hadoop cluster fired up with Whirr and running MapReduce on a dataset.
References
AWS
Hadoop
Hive
MySQL
Whirr
Amazon Public Data Sets
Wikipedia Traffic Statsand Raw Data
1) get a version of TrendingTopics.org site up and running.
2) apply that knowledge to big dataset management tasks back at work
Pete's guide is a fabulous open source resource. However, it has been two years since he wrote the application and a lot of the details about how each piece of software works have changed slightly or have been deprecated. (Funny how web technology techniques become obsoleted in two years!)
Rather than get into the nitty gritty details, I think it would be helpful to take a step back and visualize the architecture that I am trying to replicate as a whole. It is not inconsequential:

With that baseline set, I will delve into the more technical details of the project implementation in my upcoming posts.
next steps: getting a Cloudera-Hadoop cluster fired up with Whirr and running MapReduce on a dataset.
References
AWS
Hadoop
Hive
MySQL
Whirr
Amazon Public Data Sets
Wikipedia Traffic Statsand Raw Data
Subscribe to:
Posts (Atom)